来源:互联网作者:编辑点击:


基于上下文的离线元强化学习Context-based OMRL通过构建一个上下文编码器,将收集到的上下文数据映射到任务表征,进一步基于任务表征来自适应的在多个环境中进行决策。然而,在离线的情形下,任务表征的编码器极大的依赖于用于训练的离线数据的丰富程度。当数据采集有限,以至于与特定采样策略的特点耦合时,学习的任务编码器通常会难以获得较好的泛化能力,进而影响元强化学习的性能。
基于此,南京大学amp;南栖仙策团队合作提出了一种基于模型对抗样本增强的环境特征编码器学习,task Representation learning via adversarial Data Augmentation ReDA算法, 并发表在AAMAS24会议上。这一方法可以应用于元强化学习的环境特征识别上,缓解了以往算法中环境特征和采样策略耦合的影响,从而使得我们在样本受限的实际场景中可以提升环境特征编码器的泛化能力,进而提高元学习策略的表现,推进强化学习在现实世界的应用落地。
离线元强化学习环境特征耦合问题
离线元强化学习Offline Meta Reinforcement Learning是一种重要的机器学习技术,其结合了离线和元学习两种方法优势,可以帮助智能系统从以往的多种环境的离线经验中学习,以提高在新环境下的泛化能力。 通过离线数据,系统可以更有效地利用以往的经验,而无需实时与环境进行交互,从而提高数据利用效率。并且,由于在不同的环境下进行学习,而不仅仅是在当前环境下,也极大的提高了策略的泛化能力。
在很多实际应用中,实时与多种环境交互收集数据可能会很昂贵或不切实际,离线元强化学习为这些场景提供了解决方案。离线元强化学习可以使强化学习技术更易于应用和部署,在提高泛化能力、数据效率、稳健性以及降低成本等方面具有重要意义, 尤其是在实际应用中,如机器人控制与路径规划、自动驾驶系统、智能游戏角色、智能物流和仓储以及工业自动化等方面具有广泛的用途。
离线元强化学习中,主要的方法是基于上下文的离线元强化学习。该类方法将策略建模为两部分:第一部分是环境特征提取器,可以将历史收集到的上下文数据映射到环境特征上;第二部分是基于环境特征的条件策略,在给定的当前状态和得到的环境特征的条件下进行决策。第一部分的任务编码器是非常重要的,提取的环境特征将直接决定了下游的元策略的学习质量和泛化能力。
然而,以往的环境特征编码学习需要依赖非常丰富且多样的数据进行学习,这在很多真实的物理场景中是不现实甚至存在一定危险的,比如机器人等。以往的工作中,环境特征提取是基于对比学习直接在离线数据集上进行训练的:
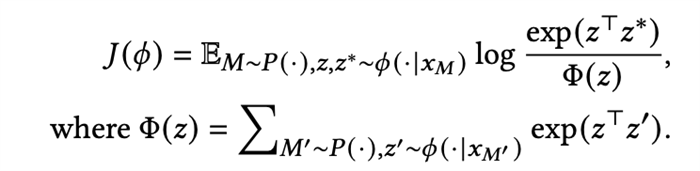
由于对比学习直观上就是减小相同任务的上下文表征的距离,增大不同环境的上下文表征的距离,通常需要收集到非常丰富的离线数据集来获得一个鲁棒且可泛化的环境表征,例如CORRO[1]需要使用整个训练期间的所有策略检查点来收集数据,这在真实场景中是不现实的,显然整个训练流程中的数据对于现实任务例如机器人控制任务是很难获取的,甚至获取过程中存在一定的不安全因素。因为很多时候我们无法获取如此丰富的样本来训练一个好的环境特征编码器,所以我们需要去关注数据集有限时环境编码器的学习问题。
简单以倒立杆任务InvertedPendulum为例,我们的训练数据是重力1.0下的高质量数据和重力2.0下的低质量数据,然后使用上下文数据是1.0倍重力下的低质量的数据进行测试图1-a,对数据集的分布进行降维可视化展示图1-b,发现测试数据到同样环境下的训练数据的距离,并没有相对其他环境的训练数据的距离更加接近图1-c,这样的情况下,仅仅依赖于数据集的对比学习,由于缺少足以代表环境任务特征的样本,将很难保证任务表征的泛化能力。
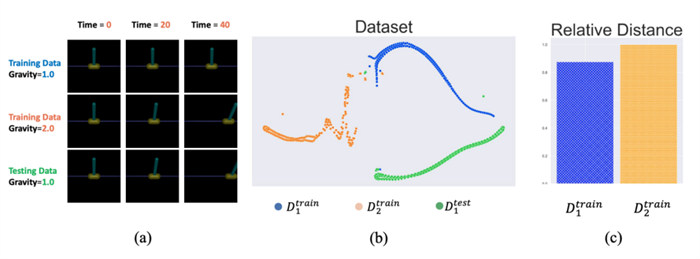
图1. a.训练数据和测试数据 b.数据分布的可视化 c.测试数据到不同任务的训练数据的相对距离
基于模型的对抗样本增强
为了让环境特征编码器更好地捕捉到环境特征而非采样策略本身的特征,我们提出了一种基于模型的对抗样本增强的方法,产生更多的不同于数据集的数据来训练环境特征编码器。
首先我们基于每个任务的数据集,分别学习各个任务上的转移模型:
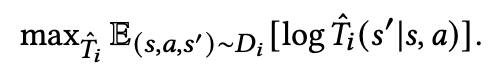
在学习好可以用来交互的环境模型后,接下来我们需要面临的问题是:1.采集什么样的样本来有效增强任务编码器的能力?2.如何缓解环境模型误差带来的影响?
对于这两个问题,我们引入了一个对抗采样策略,该策略的优化目标主要由三部分组成:
· 最小辨识度的样本:我们需要采集让任务编码最难区分的样本,即该样本到相同任务的距离和到其他任务的距离差距不大。所以我们考虑这样的样本需要具备的特点是,当它被加入上下文之后,会导致基于上下文的对比学习的损失函数上升。所以我们使用该损失函数变化的程度来作为优化的奖励信号,如果对比损失上升越大,说明该样本的引入使得任务编码器更加难以识别环境了。定义该样本加入前的任务表征为z_t,加入该样本后的任务表征为z_t+1,单步的奖励定义为:
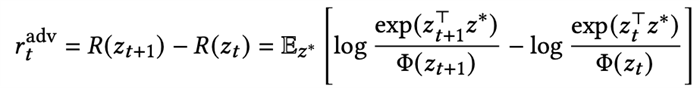
· 模型不确定性惩罚:我们并不希望对抗策略去搜索模型中误差过于大的区域,所以参考MOPO我们基于不确定性度量给出对样本的惩罚。
· 任务相关奖励:我们使用了任务的奖励函数来避免对抗策略去搜索和任务无关的样本。
综上所述,我们最终得到了在模型上搜索对抗样本的对抗策略的优化目标:
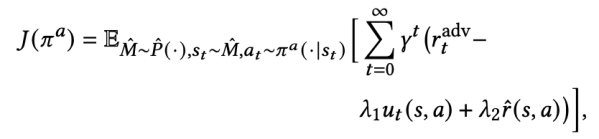
基于该对抗策略搜索到的增强样本,我们得到了新的环境特征编码器的优化目标:
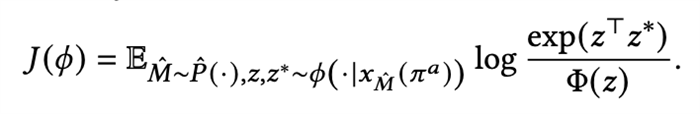
该目标是一个标准的强化学习的定义,所以可以使用SAC等算法求解。
整体的算法流程如下图所示,首先基于离线数据集学习转移模型,然后在转移模型上获得对抗策略,并产生对抗数据训练任务编码器,再基于任务编码器训练最终的元策略。
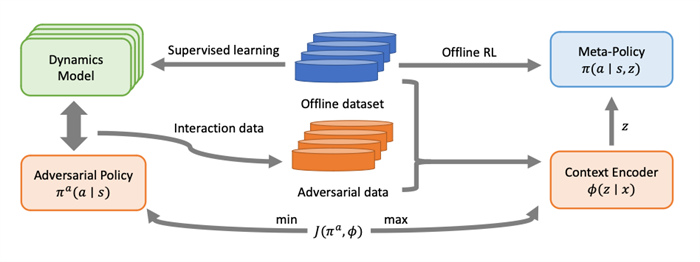
图2.算法流程
整体训练的算法描述如下:

技术验证
基于倒立杆的环境与数据集,我们对我们的方法进行了简单的验证,首先定义相对距离:

该距离描述了相同任务下训练集和测试集的距离与不同任务下训练集和测试集的距离的差异,如果该距离越小,说明我们的表征训练的泛化能力越好,通过和FOCAL[2]等基础算法进行对比,我们发现ReDA显著的提升了表征的泛化能力图3-b,并且取得了更好的测试性能图3-a。这一结果表明,我们学习到的环境表征解耦了采样的策略特征,从而更好的泛化到了更多数据上。
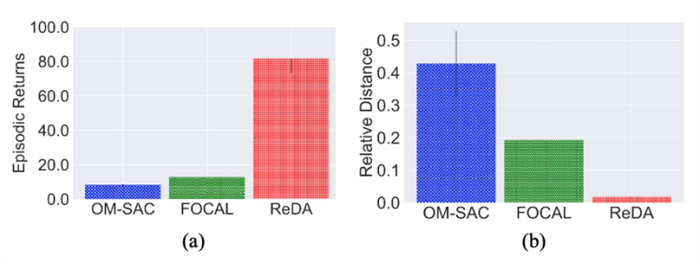
图3.倒立杆多种方法下的表征与性能
整体性能
我们设计了两种模式进行测试,第一种是on-policy模式,上下文的样本来源于当前策略的采样;另一种是off-policy模式,策略来源于数据集以外的其他样本。这两者都是在实际部署时最常需要使用的上下文样本,并且都存在和训练集存在一定的偏差。我们参考以往的工作构建了MuJoCo上的多任务数据集,包括HalfCheetah、Hopper、Walker2d、Ant在Gravity、Dof-Damping等模拟器参数变化下的多任务数据集。在训练过程中我们只使用几个检查点的数据,然后使用其他检查点的数据作为off-policy模式下的测试数据。实验结果如下:
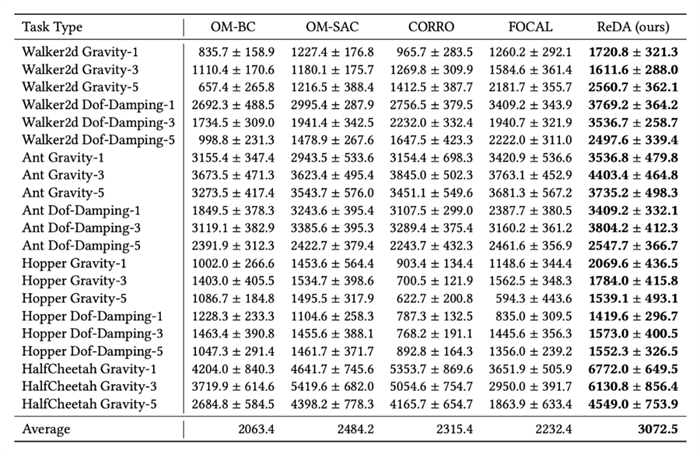
图4. on-policy模式下的性能
其中[任务] [参数类型]-[数字]的格式表示使用的训练数据集是哪个任务的哪类参数,总共使用了几个检查点的数据去训练。
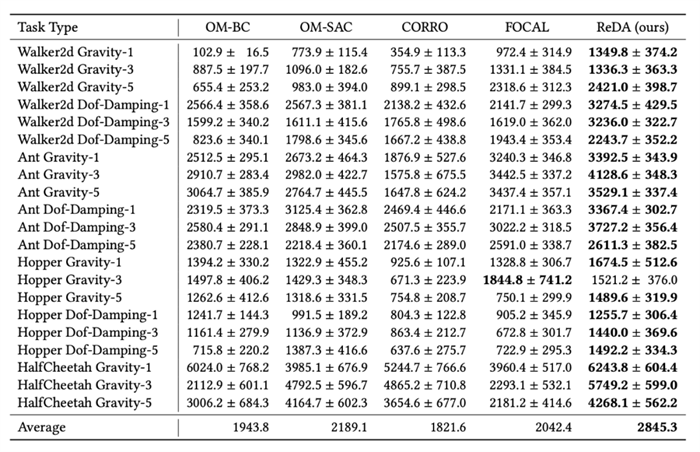
图5. off-policy模式下的性能
其中[任务] [参数类型]-[数字]的格式表示使用的训练数据集是哪个任务的哪类参数,总共使用了几个检查点的数据去训练。
可以看到,通过引入基于模型的方法,学习一个泛化能力更强的环境特征提取器,极大地提高了元策略的表现,使离线元强化学习得以在样本受限的情况下仍然取得一个不错的性能。
本文关注低数据情境下的离线元强化学习OMRL,强调了环境表示学习与数据收集策略分离的重要性,并提出了对抗数据增强的实际解决方案;训练了转移模型和对抗性策略来增强离线数据集,以应对数据集受限的情况。希望这项研究能够激发对数据采样策略在元强化学习中的影响,以及OMRL测试基准标准化的进一步探索。
参考文献
[1]. Haoqi Yuan et al. obust Task Representations for Offline Meta-Reinforcement Learning via Contrastive Learning. ICML 22
[2]. Lanqing Li et al. FOCAL: Efficient Fully-Offline Meta-Reinforcement Learning via Distance Metric Learning and Behavior Regularization. ICLR 21







